Thực đơn
Phân_tích_tần_suất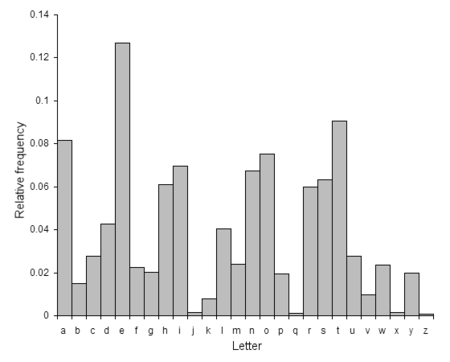
Phân_tích_tần_suất
Trong phân tích mật mã, phép phân tích tần suất là phương pháp thường dùng để phân tích mật mã cổ điển, bằng cách tính tần suất các ký tự hoặc nhóm ký tự trong bản mã và so sánh với tần suất thực tế trong các văn bản thường.Nguyên lý của phân tích tần suất dựa trên một thực tế là trong mỗi ngôn ngữ, mỗi ký tự trong bảng chữ cái có một tần suất xuất hiện nhất định. Tần suất này càng rõ ràng khi văn bản phân tích càng dài. Ví dụ trong tiếng Anh, E, T, A và O là những chữ cái xuất hiện nhiều nhất, trong khi Z, Q và X lại rất hiếm hoi. Tương tự, ta có TH, ER, ON, và AN là các nhóm ký tự phổ thông nhất, còn SS, EE, TT, và FF là các bộ đôi ký tự lặp xuất hiện nhiều nhất[1]. "ETAOIN SHRDLU" là 12 ký tự có tần suất cao nhất trong một văn bản tiếng Anh thông thường.Trong một số bản mã, khi một vài đặc trưng ngôn ngữ được tìm thấy, rất có thể nó có thể bị phá vỡ bằng tấn công chỉ từ bản mã.
Liên quan
Tài liệu tham khảo
WikiPedia: Phân_tích_tần_suất