Thực đơn
Dữ_liệu_lớn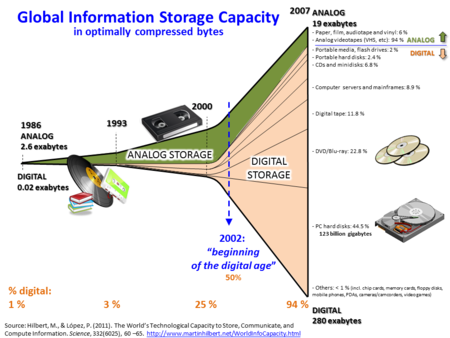
Dữ_liệu_lớn
Dữ liệu lớn (Tiếng Anh: Big data) là một thuật ngữ cho việc xử lý một tập hợp dữ liệu rất lớn và phức tạp mà các ứng dụng xử lý dữ liệu truyền thống không xử lý được. Dữ liệu lớn bao gồm các thách thức như phân tích, thu thập, giám sát dữ liệu, tìm kiếm, chia sẻ, lưu trữ, truyền nhận, trực quan, truy vấn và tính riêng tư. Thuật ngữ này thường chỉ đơn giản đề cập đến việc việc sử dụng các phân tích dự báo, phân tích hành vi người dùng, hoặc một số phương pháp phân tích dữ liệu tiên tiến khác trích xuất giá trị từ dữ liệu mà ít khi đề cập đến kích thước của bộ dữ liệu.[2] "Vài nghi ngờ cho rằng số lượng của dữ liệu có sẵn hiện nay thực sự lớn, nhưng đó không phải là đặc trưng phù hợp nhất của hệ sinh thái dữ liệu mới này."[3]Phân tích tập dữ hợp liệu có thể tìm ra tương quan mới tới "xu hướng kinh doanh hiện tại, phòng bệnh tật, chống tội phạm và vân vân".[4] Các nhà khoa học, điều hành doanh nghiệp, y bác sĩ, quảng cáo và các chính phủ cũng thường xuyên gặp những khó khăn với các tập hợp dữ liệu lớn trong các lĩnh vực bao gồm tìm kiếm internet, thông tin tài chính doanh nghiệp. Các nhà khoa học gặp giới hạn trong công việc cần tính toán rất lớn, bao gồm khí tượng học, bộ gen,[5] mạng thần kinh, các mô phỏng vật lý phức tạp, sinh vật học và nghiên cứu môi trường.[6]Tập dữ liệu đang tăng rất nhanh một phần vì chúng được thu thập bởi số lượng thiết bị internet vạn vật ngày càng rẻ và nhiều, ví dụ như các thiết bị di động, anten, nhật ký phần mềm, các thiết bị thu hình, thu thanh, đầu đọc RFID và mạng cảm biến không dây.[7][8] Khả năng lưu trữ thông tin của thế giới đã tăng bình quân gấp đôi sau mỗi 40 tháng từ những năm 1980[9]; riêng năm 2012, mỗi ngày thế giới tạo ra 2.5 exabytes (2.5×1018)[10]. Một câu hỏi cho các tổ chức kinh doanh lớn là xác định ai nên sở hữu các sáng kiến dữ liệu lớn có ảnh hưởng tới toàn bộ tổ chức.[11]Hệ quản trị cơ sở dữ liệu quan hệ, máy bàn và các gói ảo hóa thường khó xử lý dữ liệu lớn. Công việc khổng lồ này yêu cầu được xử lý bởi hàng chục, hàng trăm, hoặc thậm chí hàng nghìn máy chủ.[12] Người ta quan niệm dữ liệu lớn khác nhau phụ thuộc vào khả năng của người dùng và công cụ họ dùng, và khả năng mở rộng làm cho dữ liệu lớn luôn thay đổi. "Các tổ chức đối diện với hàng trăm gigabytes dữ liệu ở thời gian đầu gây ra sự cần thiết phải xem xét lại các tùy chọn quản trị dữ liệu. Mặt khác, có thể tạo ra hàng chục hoặc hàng trăm terabytes trước khi kích thước dữ liệu trở thành một lý do quan trọng".[13]
Liên quan
Tài liệu tham khảo
WikiPedia: Dữ_liệu_lớn